Disclaimer: I am not an expert and nothing in this post should be taken as advice.
If a lead rope solo (LRS) climber could carry a rope for each pitch of a multipitch route, and all gear needed without reusing any, then each pitch could be climbed just once using the "regular" LRS method. Otherwise, for each pitch, the climber must lower, clean gear, untie the lead rope from the anchor, and re-climb or ascend the pitch (see Brent Barghahn's "Redpoint Rope Soloing Revised" for an overview of a modern LRS system). The modified LRS method below could be used to climb each pitch once, reusing the same rope for each pitch, but still requires the climber to carry all anchor and protection gear needed without reusing any.
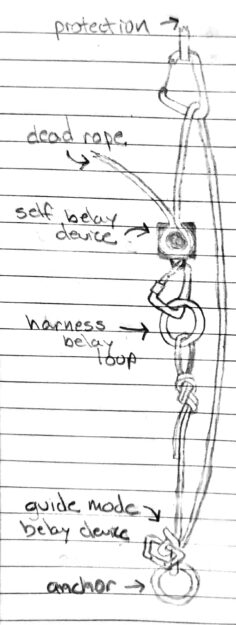
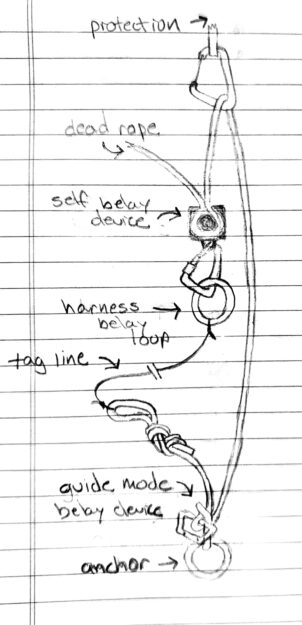
Method: Like "regular" LRS, the lead rope is fixed to an anchor then passes up through protection and back to the climber through a self-belay device. However, at the anchor, the rope is fixed using a tube device in guide mode (e.g., the Black Diamond ATC Guide) that permits upward progress but blocks during a fall (see diagram below). The anchor end of the rope is tied to a tag line attached to the climber. While climbing, the tag line is extended as needed such that the lead rope remains stationary. At the top of each pitch, the climber disconnects the rope from the self-belay device and pulls the tag line and lead rope from the opposite end, through all of the protection, through the tube device at the anchor, and back up to the climber. This frees the rope for the next pitch where the process is repeated. At the top of the final pitch, the climber rappels and cleans each pitch.
The main benefit of this technique is to climb each pitch without lowering and re-climbing, and still be able to reuse the rope. There are several drawbacks, relative to the "regular" LRS method:
- Lead climbing is not listed as an application for some tube devices in guide mode (e.g., the Mammut Wall Alpine Belay). The configuration depicted above is further complicated because it's upside down from the usual guide mode, and because the "brake" side is dangling free. The consequences of a lead fall on a tube device in this configuration are unclear.
- This method requires enough anchor and protection gear for all pitches without reuse, including an extra tube device in guide mode for the anchor of each pitch. And, all gear is left in place until the final descent. A shorter sport route, such as Star Chek (3 pitches, 16 bolts total) might be suitable for this method.
- The rope may get stuck while pulling the end through the tube device.
- Due to the previous concern, it's risky to lead more than 1/2 of the rope length.
- Backfeed prevention widgets may prevent rope retrieval.
Variation: Instead of tying the lead rope to a tag line, it can be tied directly to the harness. While climbing, both ends of the lead rope move upward. See diagram below. However, there is significant rope friction due to movement through the tube device and protection each time the climber moves upward.